
点击数:2471
1. 特征选择
1.1. 定义与作用
当数据挖掘和机器学习算法应用于高维数据时,如果数据特征属性过多,会造成维数灾难。随着数据特征的增多,模型过拟合的风险会增加,导致在面对陌生数据时模型的能力下降。此外,高维的数据对计算成本和存储成本的需求也会增加。
降维是解决这一问题的有效手段。降维主要分为两种:特征抽取 (feature extraction) 和特征选择 (feature selection)。特征抽取一般指将原始的高维特征空间投影到一个新的低维特征空间。特征选择,则是直接从原始特征中选取用于模型构建的最相关的一些特征1。
1.2. 常用方法[2]
1.2.1. 过滤式 (Filter)
过滤式方法先对数据集进行特征选择,然后再训练模型。特征选择过程与后续的模型训练过程解耦。即先用特征选择过程对初始特征进行“过滤”,再用过滤后的特征数据进行训练。
过滤式方法是根据数据的一般特征而不是具体的算法模型来选择最佳特征子集。通常,过滤器 (filter) 根据特定的评估标准计算特征(子集)的分数,然后选择得分最高的特征。评估标准可以是针对多特征或单特征。多特征度量考虑特征集内的特征间的关系,单特征度量独立地评估每个特征。因此,多特征度量可以检测冗余特征,更通用。3
1.2.2. 包裹式 (Wrapper)
包裹式特征选择直接把最终将要使用的模型性能作为特征子集的评价准则。即,包裹式特征选择是为特定模型选择最有利于其性能、“量身定做”的特征子集。因此效果通常比过滤式更好,但其计算成本也更高。首先,wrapper 类的方法通过需要一个搜索策略来得到特征子集;其次,特征子集的质量是通过一个模型算法来评估的。需要重复整个过程直到停止策略生效。
1.2.3. 嵌入式 (Embedded)
嵌入式方法是介于过滤式和包裹式之间的一种平衡策略,它将特征选择的过程融入到模型的训练中。相比于过滤式,特征能根据算法模型进行选择;不同于包裹式,它不需要迭代的重复的去评估特征子集。
1.3. 过滤式特征选择方法 (Filter)
1.3.1. 单变量过滤式[4]
1.3.1.1. 低方差过滤
思想:移除某一特征,其特征值方差很小。
限制:只有当特征值在同一度量标准下(same scale)并且未按标准差归一化时适用。仅限数值特征。
实现: sklearn.feature_selection.VarianceThreshold
1.3.1.2. Pearson 相关系数
思想:通过协方差和标准差的商(皮尔逊相关系数)衡量两个变量之间的线性关系
限制:只能计算线性关系
实现: sklearn.feature_selection.f_regression
1.3.1.3. 卡方检测
思想:卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大。则可利用卡方检测检测特征与标签的独立性,如果独立,则可以删除该特征。
实现: sklearn.feature_selection.chi2
1.3.2. 基于特征重要性的过滤式
1.3.2.1. 随机森林特征重要性
- permutation importance:
思想:对于每棵树的袋外样本 (out of bag),将这些样本的特征 Xk 随机置换。置换后的样本通过相应的树模型进行分类,分类结果与没有进行置换的结果对比。permutation importance 的结果就是对比结果精度的减少值。对于分类结果重要的特征会导致结果下降很多,因为特征相关的信息经过置换后缺失。
实现: eli5.sklearn.PermutationImportance or sklearn.inspection. permutation_importance
- impurity importance (Mean Decrease in Impurity):
思想:利用不纯度可以确定节点(最优条件),对于分类问题,通常采用 基尼不纯度 或者 信息增益 ,对于回归问题,通常采用的是 方差 或者最小二乘拟合。当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
注意:该重要性是在训练集上统计而来的,因此,在测试集上可能有误差;第二,该方法更喜欢特征有很多不同的值的特征(high cardinality features)。
相关资料:https://mljar.com/blog/feature-importance-in-random-forest/
https://scikit-learn.org/stable/auto_examples/inspection/plot_permutation_importance.html
1.3.3. 基于互信息的过滤式
1.3.3.1. 信息增益过滤
整体思想:熵是衡量变量不确定性的指标。两个变量的互信息可以表示为: I(Y;X) = H(Y) – H(Y|X) 。即在已知条件 X 下,Y不确定性的减少程度。即可衡量变量 X 和变量 Y 的相关性。
- Maximum Relevance Minimum Redundancy(MRMR):
思想:最大化特征和标签之间的相关性,最小化特征与特征之间的相关性。即:
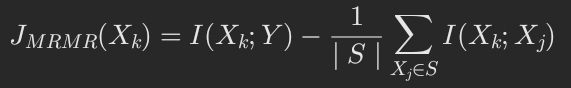
实现:http://home.penglab.com/proj/mRMR/
注意:离散变量效果更好,如果是连续型变量,可先离散化
Joint Mutual Information Maximum(JMIM):
思想:特征之间互相相关不代表特征是冗余的,因此上述MRMR方法会过滤掉非冗余的特征。而最大化联合互信息在选择特征时,还考虑了在有分类条件下子集特征与未选特征之间的互信息大小。公式表示即:
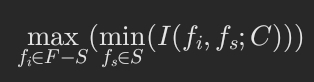
其中:
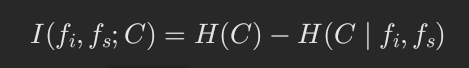
实现: mifs 包:http://www.github.com/danielhomola/mifs
1.4. 包裹式特征选择方法 (Wrapper)
Wrapper算法的思想是:和学习算法无关的过滤式特征评价会和后续的算法模型产生较大的偏差,而学习算法基于所选特征子集的效果可以作为更好的特征评价指标。
wrapper算法一般步骤
1.4.1. 顺序选择算法
顺序选择算法从一个空集(全集)开始,增加(减少)特征直到获得最大目标函数。为了加速选择过程,会设定一个标准,使用最少的特征数达到最大的目标函数。
1.4.1.1. The Sequential Forward/Backward Selection
思想:特征子集X从空集开始,每次选择一个使得目标函数最优的特征x加入特征子集。
缺点:不考虑特征间的冗余。特征一旦加入不会被删去。
实现: sklearn.feature_selection.RFE
1.4.1.2. Sequential Floating Forward Selection
思想:序列浮动选择根据搜索方向的不同,有以下两种变种:
前向浮动(SFFS):从空集开始,每轮在未选择的特征中选择一个子集x,使加入子集x后评价函数达到最优,然后在已选择的特征中选择子集z,使剔除子集z后评价函数达到最优。
后向浮动(SFBS):与SFFS类似,不同之处在于SFBS是从全集开始,每轮先剔除特征,然后加入特征。
特点:一定程度上能去除冗余特征。
1.4.2. 启发式搜索算法
启发式搜索算法对不同的子集进行评估来优化目标函数。可以通过搜索空间内搜索产生特征子集或通过生成式的方案优化目标问题。
1.4.2.1. 遗传算法(GA)
思想:通过模拟生物的选择和繁殖进行随机的信息交换来完成的。待解决的问题通过编码为多个基因构成的染色体来描述。每个染色体都有一个适应值,由适应函数评价得到。可以判断染色体的好坏及其生存概率。如图所示6:
遗传算法图解(// 图片不在电脑上,待补后续)
遗传算法的个体是长度为 n 的二进制串, n 为特征数目,第 i 位为0表示不选择特征。
缺点:容易过早收敛,并且用于大规模数据时,运行效率较低。
1.5. 嵌入式特征选择方法 (Embedded)
嵌入式特征选择将特征选择过程带入到模型训练的过程中,因此,该方法的计算成本较wrapper的方式更低。对于嵌入式方法,稀疏学习算法运用较广,因为他们效果好,解释性强。
1.5.1. 正则化(l1 正则—Lasso / l2 正则)
思想:l1 正则化将系数 w 的 l1 范数作为惩罚项加到损失函数上,由于正则项非0,则迫使特征系数矩阵 w 更小,则特征弱的系数项趋近于0。达到稀疏性。
特点:既能防止过拟合,也能通过稀疏性稀疏矩阵获得特征项。
1.5.2. 基于树模型的特征选择
思想:由于决策树算法在构建树的同时也可以看作是进行了特征选择,因此可以利用树算法本身进行特征选择
实现: sklearn.feature_selection.SelectFromModel 可以与任何在拟合后具有 coef_ , feature_importances_ 属性或参数中可选惩罚项的评估器一起使用。
随机森林和树模型 就具有属性 feature_importances_
1.6. 经验评价与可用算法包
从论文5对 filter 式的特征选择结论来看,基于随机森林的特征重要性过滤方式表现最好,其次是 JMIM 算法;
wrapper 式中启发式搜索的代价较大,且易过拟合,一般采用 序列浮动选择或相关改进方法;
embedded 式特征选择方法一般结合 正则化和基于树模型的特征选择。
2. 实现
https://github.com/Junphy-Jan/Feature_Selection
基于RAY框架,实现了9种特征选择算法:

输入仅需要 csv 或 parquet 文件即可。
留言