
点击数:989
https://arxiv.org/abs/2301.12597
摘要
提出了 BLIP-2, 一个通用且高效的预训练策略,利用已有的冻结的预训练图像编码器和冻结的大型语言模型来引导视觉-语言的预训练。
BLIP-2利用一个进行两阶段训练的轻量的 Querying Transformer 结构弥补了不同模态之间的鸿沟。第一个阶段使用冻结的图像编码器来引导 视觉-语言表征学习,第二阶段利用冻结的语言模型引导 视觉到语言的生成式学习。
1. 介绍
利用预训练的单模态模型进行视觉-语言预训练(Vision-language pre-training(VLP)),关键是解决多模态的对齐问题。然后,由于LLMs在进行单模态训练时从未见过图像,冻结LLMs来使视觉和自然语言对齐是很困难的,对此,当前的方法,如Flamingo,采取了 图像到文本生成的loss方式来进行学习。然而我们发现这其实对填补不同模态之间的gap是不够的。
为了有效地利用冻结的单模态模型进行对齐视觉和自然语言,我们提出了 Querying Transformer(Q-Former).

如图所示,Q-Former 是一个轻量的 transformer 结构,采用一组可学习的 query vectors 从冻结的图像编码器来提取视觉特征。它就像一个在冻结的图像编码器和冻结的LLM之间的信息瓶颈,将视觉编码器中最重要的信息喂入LLM来产生想要的文本输出。
在第一个预训练阶段,我们通过 视觉-语言表征学习来让 Q-Former 学习到与对应文本最相关的视觉表征。在第二个预训练阶段,我们通过 视觉到语言的生成学习将 Q-Former 的输出链接到冻结的LLM中,训练 Q-Former来让它输出的视觉表征能被LLM所理解。(视觉特征对齐到自然语言特征?)
我们将它命名为 BLIP-2:Bootstrapping Language-Image Pre-training with frozen unimodal models.
BLIP-2 的关键优势包括:
- BLIP-2 高效的利用了冻结的预训练图像模型和语言模型。
- LLM 的能力,可以通过prompt表现出推理和涌现的能力。
- 高效计算,大模型都冻结了。
2. 相关工作
模块化视觉-语言预训练
有一些与 BLIP-2 相似的工作。一些方法是冻结图像编码器,一些方法是冻结语言模型。冻结语言模型的关键挑战是如何对齐视觉特征到文本空间。为此,Frozen(Tsimpoukelli et al., 2021) 通过微调一个图像编码器,使图像编码器的输出直接用作LLM的 soft prompts,来进行文本生成。Flamingo (Alayrac et al., 2022) 则是在LLM中插入交叉注意力层来注入视觉特征。这两种方法都采用的是语言模型的loss, 也就是利用图像信息作为条件,来生成相应的文本。
不同于上述方法,BLIP-2则是高效且有效的利用了冻结权重的 图像编码器和LLMs 来处理多种视觉-文本任务,从而达到了更低的计算量。
3. 模型架构
Q-Former 作为可训练的模块来连接冻结的图像编码器和LLM之间的语义空间。它能从图像编码器中抽取固定长度的特征作为输出,独立于输入的图像分辨率。如下图所示,Q-Former 由两个共享同一个 self-attention 层的transformer 子模块组成:1)一个图像 transfomer,与冻结的图像编码器交互,来提取视觉特征;2) 一个文本transformer 同时充当文本编码器和解码器。
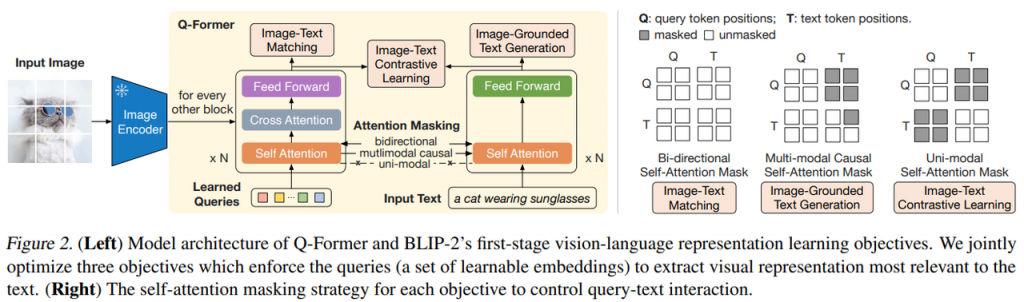
我们创建了一组可学习的 query embedding 作为 image transformer 的输入,与冻结的图像编码器通过 cross-attention层进行交互。这些查询向量还能通过相同的 self-attention 权重与文本进行交互。根据不同的预训练任务,我们采用了不同的 self-attention masks 来控制 query向量和文本的交互。Q-Former 使用 \(Bert_{base} \) 初始化,而 cross-attention层则随机初始化。最终Q-Former 共包含188M 参数,包括 queries向量。
在实验中使用了32个 queries, 每个 queries 有 768 维,与Q-Former 隐藏层维度一致(Bert的隐藏层维度)。以 Z 代表输出的 query 表示,Z的维度(32*768)远小于冻结的图像编码器的输出的特征维度(如ViT-L/14的 257*1024维)。
这种信息瓶颈架构与预训练目标一起使得能够抽取出与文本最相关的图像的信息。
3.2. 从预训练图像编码器引导 Visual-Language 表示学习
图文对比学习(Image-Text Contrastive Learning(ITC))
用于学习对其图像和文本的表示,使得图文的互信息最大化。通过对比学习的方式,图文对正样本的相似度大于负样本的相似度。特别地,对齐从 image transformer 得到的 query表示 Z 和 从 text transformer 得到的 t, t是 \([cls] \) token的embedding。由于 Z 包含多组 embedding (每个 query 都有一个),首先计算每个 query输出和t的相似度,然后取最高的一个作为图文相似度。为了避免信息泄露,引入了单模态的 self-attention mask, 其中 queries 和 text互相不可见。由于使用的是冻结的 图像编码器,可以一次喂入更多的数据,因此我们使用了 in-batch negatives 而不是在BLIP中用到的momentum queue的方法。
基于图像的文本生成(Image-grounded Text Generation(ITG))
通过给定输入图像作为条件,训练Q-Former 来生成对应的文本。由于在Q-Former的结构上不允许图像编码器的结果和文本输入直接交互,用于生成的信息必须首先通过 queries 向量的抽取,然后再通过 self-attention 层传递给文本tokens. 因此,queries 向量就被强迫的去抽取与文本相关的图像的所有信息。我们采用了多模态的 causal self-attention mask 来控制 query-text 的交互,与 UniLM (Dong et al., 2019) 使用的类似。Queries向量可以相互看到,但是看不到文本tokens,每个text tokens 可以看到所有的 queries 向量和位于它位置之前的文本。我们还使用了 \([DEC] \) 新token 来代替 \([CLS] \) token 作为第一个token来代表解码任务。
图文匹配(Image-Text Matching(ITM))
用于学习图文表示的细粒度对齐。它是一个二分类任务,模型需要判断是否图文对是正相关还是负相关的。使用了一个双向 self-attention mask,其中queries 和 text 可以相互作用。query embedding 的输出向量 Z 因此可以捕捉到多模态信息。然后我们将 query mebedding 喂入一个二分类分类器得到 logit, 平均所有 queries 的logits,得到最终的得分。同时采用了一种挖掘困难负样本的方法。
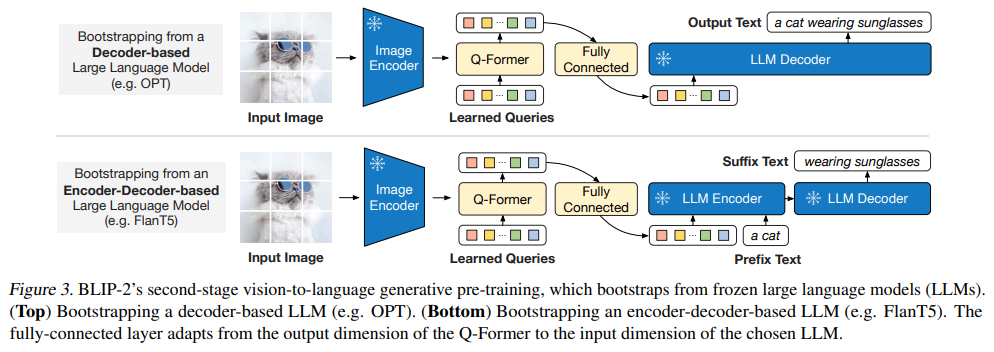
3.2. 从预训练LLM引导 Visual-to-Language 生成式学习
在生成式预训练阶段,我们将 Q-Former(带有预训练的图像编码器) 连接到LLM中来继承LLM的语言生成能力。如图3所示,以一个全连接层来将 query embeddings Z 的输出映射到LLM embedding相同的维度。映射后的 query embeddings 随后拼接到文本输入的embedding向量之后。他们的功能类似于 \(soft\ visual\ prompts \),即以 Q-Former 抽取出的视觉表征作为LLM的输入prompt。
留言