
点击数:1198
需求描述
- 需要支持分布式数据读取
- 对单个特征所有数据进行分析,如特征选择、分箱等
- 适应分布式,最小化读取中内存增加
数据格式:

Ray Datasets 结构:
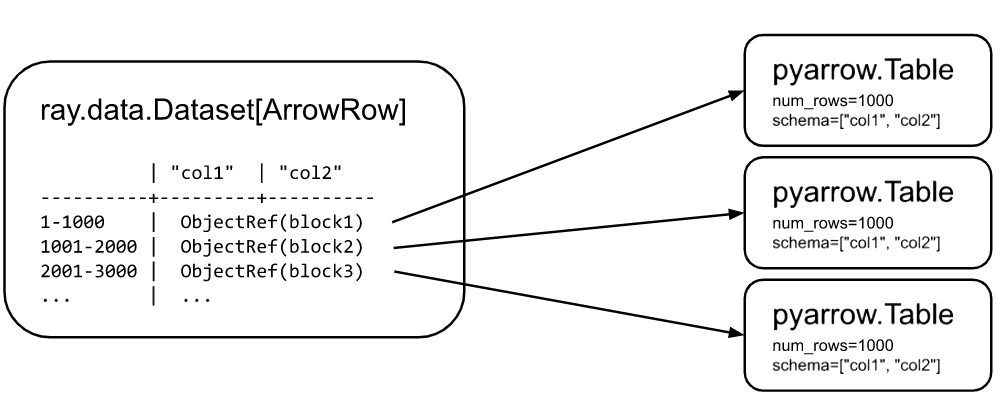
Ray Datasets 是 Distributed Arrow 的一个实现 。 Datasets 包含对块(block)的Ray对象引用列表。每个块都是 Arrow table, Arrow tensor, 或是 Python list (用于保存 Arrow 不兼容的对象)的一系列集合。Datasets 中具有多个块能够允许并行的对快进行转换和读取数据。
代码:
@ray.remote
def aggregate_col(block: pyarrow.lib.Table, zero_copy_only=True):
print("block type:{}".format(type(block)))
block_data: pyarrow.lib.Table = block
feature_data = []
schemas = block_data.schema().names
for feature_name in schemas:
feature_column_data: pyarrow.lib.ChunkedArray = block_data[feature_name]
feature_col_np_data: np.ndarray = feature_column_data.combine_chunks().to_numpy(zero_copy_only=zero_copy_only)
feature_data.append(feature_col_np_data)
del feature_col_np_data
return feature_data
start = time.time()
ray.get([aggregate_col.remote(block) for block in dataset.get_blocks()])
print("read feature data duration with parallel:{}".format(time.time() - start))
留言