
点击数:655
(查UDA的时候,看到很多博主写的是无监督数据增强,一开始以为是一种无监督数据增强的手段,兴冲冲的看了下,发现机翻害人!通读全文,这篇论文讲的是在 对 无监督数据 以及 经过数据增强后的数据 的一种训练方式,即主语是 Consistency Traning)
注:如公式显示不正确请安装 MathJax 插件
作者:

摘要
尽管深度学习在很多方面都成功了,但在小样本训练集上的表现通常并不好。在这种场景下,数据增强在减轻对更多标注样本的需求上有一定的能力,但是到目前为止,其更多的被用于有监督的学习,并且达到的效果有限。在我们的工作中,我们将数据增强用于半监督学习的无标注样本。我们使用的方法——Unsuperivsed Data Augmentation 即 UDA,促使模型在无标签样本和经过数据增强的无标签样本中表现一致。不像以前的方法,他们使用随机噪声例如高斯噪声或dropout噪声,UDA 使用的噪声来自于通过目前最好的数据增强手段增强的数据,并在6个NLP任务和3个图像任务中取得了很可观的提升,即使是在标注数据很少的情况下。
1. 介绍
深度学习往往要求许多有标签的数据才能表现较好。然而,标注数据往往是个成本很高的步骤。因此,使用无标签数据来提高深度学习的表现就成为了(资本家的(/s))一个很重要的手段。在此方向下,半监督学习是其中最有希望的一个方法,最近的一些工作可以归为以下几类:(1) graph-based label propagation via graph convolution [31] and graph embeddings (2) modeling prediction target as latent variables [30], and (3) consistency / smoothness enforcing [2, 35, 44, 7, 58]. 在以上几类中,最后一种方法在最近的工作中都显示其很有效果。
概括来说,the smoothness enforcing methods 调整模型的预测,使之对样本(有标签或无标签)的噪声的敏感性更低。给定一个观察样本, smoothness enforcing methods 首先创造一个扰乱版本的样本(例如,典型地如添加人工噪声,如高斯噪声或dropout),然后强制模型对这两个样本的预测相似。直观地,一个好的模型应该对任何不改变样本本质的所有小的扰动表现一致。在这种指导思想下,这类方法最大的不同是添加扰动的方法不同,如,扰动(有噪声)的样本是如何创造的。
在我们的工作中,我们提出了利用 有监督学习的 state-of-the-art 的数据增强方法作为扰动方法,在 smoothness enforcing 框架下,扩增先前 Sajjadi et al. [52], Laine and Aila [35] 等人的工作。我们发现更好的数据增强方法能带来更好的提升,并且能用于其他的很多领域。我们的方法,UDA,最小化 模型 在 原始数据 和 数据增强后的数据 下的 预测 的 KL散度。尽管数据增强已经被研究的很多了,也带来了一些有意义的提升,但是它更多的被用于有监督的学习。UDA,另一方面, 在无标注数据下也能直接利用 state-of-the-art 的数据增强方法。我们认为比在有监督的任务中利用数据增强更有潜力。
下面说说我们的UDA方法有多好,balabalabala…(主要是说利用较少的标签数据就能达到利用很多标签数据就能达到的效果)
我们这篇文章的贡献:
首先,我们提出了一种训练技术——TSA,有效地防止当无标签数据比有标签数据多得多地情况下的过拟合。
其次, we show that targeted data augmentation methods (such as AutoAugment [9]) give a significant improvements over other untargeted augmentations.
第三,在很多的NLP数据增强手段上我们的方法都有效,并且补充了表示学习的方法,如bert
第四,无论是在NLP还是在CV上,我们的方法比之前的方法好多了
最后,我们还使用了一种方法,让UDA可以解决有标签数据和无标签数据在类别分布不匹配情况下也可以使用( Finally, we develop a method so that UDA can be applied even the class distributions of labeled and unlabeled data mismatch )
2. Unsupervised Data Augmentation (UDA)
在本节,我们首先通过公式表达任务,然后提出我们的方法,UDA。在这篇论文中,我们主要关注分类问题,记输入为:x ,y(x) 或 y* 表示真实预测值。我们的目的是学习一个模型 $p_{\theta}(y\mid x)$ 基于 x 预测 y* ,其中 ${\theta}$ 是模型参数。另外分别用 L 和 U 表示有标签数据和无标签数据
2.1 背景:有监督数据增强
数据增强致力于在不改变数据标签的情况下,通过对一个样本施加变换等操作生成一个新的,相似样本。即通过
有监督的数据增强可以看作是在原有监督数据集上构造一个增强的标签数据集,再在增强的标签数据集上进行训练。因此,增强的数据必须提供额外的归纳噪声(inductive biases)才能更有效。因此,如何设计增强的变换方式就变得很重要。
在最近几年,在NLP,vision 和 speech 领域数据增强方法有了很大的进步。尽管如此,数据增强仍然被视为“蛋糕上的樱桃”(cherry on the cake),只能提供一点微小的贡献,因为目前数据增强只能用在有标签数据上,而有标签数据量一般都比较小。受限于此,我们开发出了 UDA 让数据增强能用于无标签数据,而无标签数据往往数据量很大。
2.2 无监督数据增强(UDA)
正如 介绍 中讨论的,最近在半监督学习中的一些工作是利用未标记的样本来增强模型的平滑性。这些工作一般是这么做的:
- 给定输入 $x$,计算输出分布 $p_{\theta}(y\mid x)$ 和一个增加噪声 $\epsilon$ 的版本 $p_{\theta}(y\mid x, \epsilon)$ 。噪声可以是对输入 $x$ 做变换或通过隐藏状态变换或者是改变计算过程来实现。
- 最小化上述两个预测输出分布 $D(p_{\theta}(y\mid x)\parallel p_{\theta}(y\mid x, \epsilon))$ 的散度变量
这就强迫模型对噪声
本文中,我们对目前的 smoothness / consistency enforcing 工作做一点小小的改动,扩展到利用数据增强来做为噪声。我们提出利用目前SOA 的数据增强变化作为 $\epsilon$ ,然后优化模型对这些无标签数据增强后和增强前的平滑性。具体地说,根据 VAT[44],我们选择最小化无标签数据增强前和增强后预测分布的 KL 散度:
$ {\color{blue} {\min_{\theta} \Im_{UDA}(\theta) = E_{x\subset U} E_{\hat{x}\sim q(\hat{x}|x)}[D_{KL}(p_{\widetilde{\theta}}(y|x) \parallel p_{\theta}(y | \hat{x}))]}}$ (1)
其中,$q(\hat{x} | x)$ 是数据增强变换,根据 Miyato et al.[44] 的建议,$ \widetilde{\theta} $是当前模型参数 $\theta$ 的一个固定拷贝,即参数 $ \widetilde{\theta} $不会进行梯度回传。此处的数据增强变换和在有标签的数据集所作的增强变化一致,如在文本上进行回译增强或在图像上进行随机裁剪等。由于训练时进行同时回译增强成本太大,所以我们是离线进行数据增强的。
为了同时使用标签数据和无标签数据,我们在有标签数据集上使用 cross entropy loss,模型的平滑按照公式(1) 并添加一个乘积因子 $\lambda$ ,最终的训练目标如下,图示如图1:
${\color{blue} {\min_{\theta} \Im = E_{x, \dot{y}\subset L}[ p_{\theta}(\dot{y} \mid x)] + \lambda \Im_{UDA}(\theta)}}$ (2)
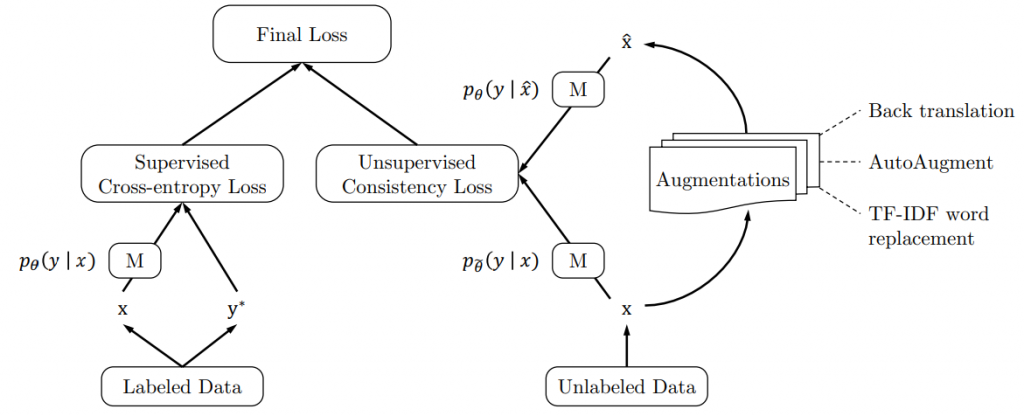
通过最小化一致性 loss,UDA 能将标签信息从有标签数据传递到无标签数据。对大部分实验,我们设置 $\lambda$ 为1,并对有标签数据和无标签数据设置不同的 batch size。我们发现在一些数据集上对无标签数据使用更大的batch size 能达到更好的效果。
后面就是些实验和训练相关的内容了,了解了训练方法剩下的如果觉得有必要的可以自己去看看如何能训练好。
综上,Google 认为数据增强效果不大是因为只能对有标签的数据进行增强,而有标签的数据量一般都比较小,不能满足大模型对大数据的要求,所以他们把无标签数据也增强然后放到训练目标里去,让模型能从无标签的数据里学到东西,间接地增强了模型能用到的数据。
留言