
点击数:1669
搜索引擎一般都由 [分词器——tokenizer、token过滤器——token filter]——analyzer 组成:
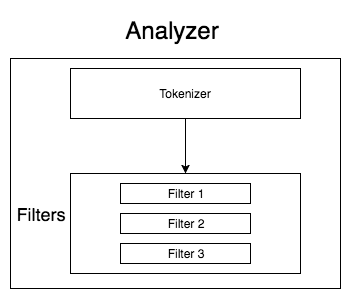
Elasticsearch 中的tokenizers:
Standard Tokenizer、 Whitespace Tokenizer、Letter Tokenizer 等。以 Letter Tokenizer 为例:The letter tokenizer divides text into terms whenever it encounters a character which is not a letter.
Input => “quick 2 brown’s fox “
Output => [quick,brown,s,fox]
更多信息参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
Token Filters
token filter 作用在由 tokenizer 产生的 token上,并根据对应的规则修改token。常见的token filter 包括:Stop token filter、Synonym token filter 等。后面会详细介绍 Synonym token filter
更多信息参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html
自定义Analyzer
指定可用的 tokenizer 和 token filter:
{
"analysis": {
"filter": {
"synonym_word_filter": {
"type": "synonym",
"updateable": "true",
"expand": "false",
"synonyms_path": "analysis/synonym.txt"
}
},
"analyzer": {
"ik_smart_synonym": { // analyzer名称
"filter": [
"synonym_word_filter" //指定filter
],
"type": "custom",
"tokenizer": "ik_smart" // 指定tokenizer,使用的是IK分词器的tokenizer
}
}
}
}
IK 分词器适用于中文分词的Elasticsearch插件,安装方式在 repo 里描述了。下面介绍如何在 Elasticsearch 7.11 版本使用同义词以及配置远程扩展词库。
配置同义词
- 创建索引时创建自己的 analyzer
- mapping 时指定 search_analyzer
- 创建同义词文件
步骤1的索引可使用上述的自定义analyzer;
mapping时,一般指定search_analyzer 使用自定义同义词analyzer,在数据存入Elasticsearch创建索引时,一般使用标准的 ik_smart 或者 ik_max_word。一个案例如下:
{
"properties": {
"question": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": " ik_smart_synonym", //上一步索引时创建的自定义 analyzer
"index": "true"
},
"answer": {
"type": "text",
"index": "false"
},
"questionId": {
"type": "integer"
}
}
}
同义词文件配置:
我是使用 dpkg 命令在Ubuntu安装的, synonym.txt 文件配置放在安装路径:/etc/elasticsearch/analysis/synonym.txt 下,你也可使用 whereis elasticsearch 查看你的安装目录,analysis目录需要自行创建。 synonym.txt 文件格式如下:
土豆,马铃薯,potato
香蕉,banana
注意到 synonym_word_filter 中设置了 expand 为 false。以上述同义词为例,如果设置 expand 为 false, 则只会将token中的“马铃薯”、“potato”、“土豆”替换成“土豆”,即以第一个词为准。如果 expand 为 true,则如果 token中出现 “土豆”,“马铃薯”,“potato”任一词,都会解析成三个token。 如果不设置此项,则默认 expand 为 true
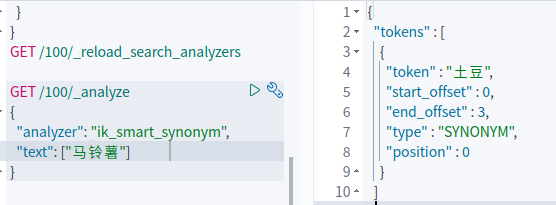
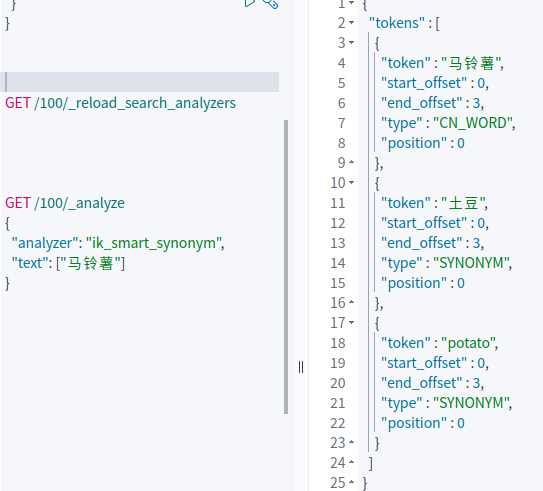
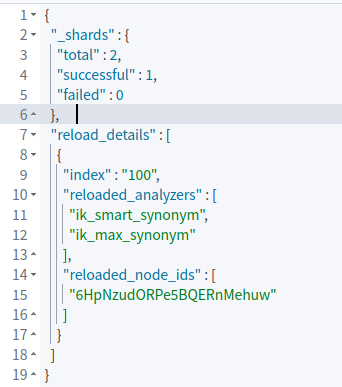
由于在创建索引时使用了 "updateable": "true" 配置,你可以在修改了 synonym.txtx 之后调用 API: POST /my-index/_reload_search_analyzers 更新 search_analyzer 的配置。
配置远程扩展词库
在 IK 分词配置下的 IKAnalyzer.cfg.xml 文件中配置远程接口或者文件URI。接口使用GET访问方式,接口的返回Header里在远程词库变化时更改 Last-Modified或者 ETag字段即可热更新。
留言