
点击数:13326
环境:
1.Neo4j database: 4.0.1 (是Neo4j graph数据库版本,非 neo4j desktop版本)
2.jdk11 (neo4j 4.0.1要求jdk需要11)
OwnThink开源了史上最大规模(1.4亿)中文知识图谱,地址:https://github.com/ownthink/KnowledgeGraphData

下载解压后查看知识图谱规模:
$ wc -l ownthink_v2.csv 140919781 ownthink_v2.csv
在github开源地址下可以找到阿里巴巴的一个下载数据源(链接 https://nebula-graph.oss-accelerate.aliyuncs.com/ownthink/kg_v2.tar.gz),下载之后解压,打开其中的 read_first.txt ,下载好简单清洗后的edge.csv和vertex.csv。

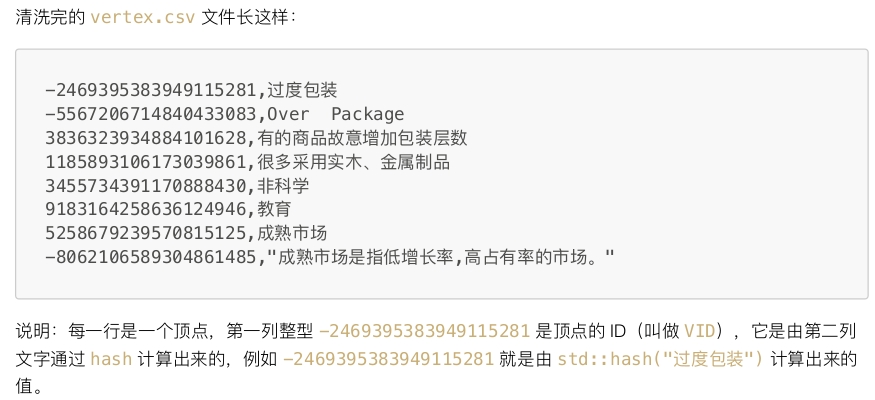
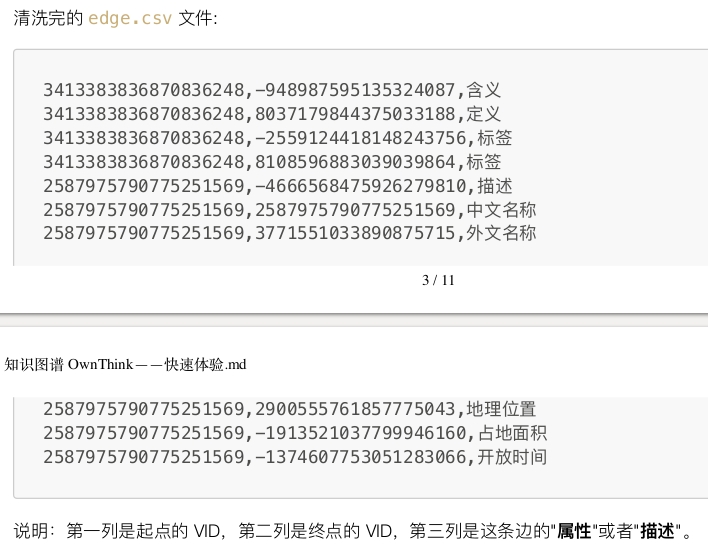
可以看到数据量很大,在阿里巴巴的压缩包中,还有一篇pdf文档,介绍了将数据导入nebula 图数据库中的步骤以及edge.csv和vertex.csv的格式,这里简单贴一下数据格式:
在网上找了一下如何导入到neo4j中,参考了:https://yuukiblog.top/2019/10/16/neo4j%E5%AF%BC%E5%85%A5%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E5%88%9D%E4%BD%93%E9%AA%8C/
Neo4j要求的数据格式(不清楚其他的格式能否导入):
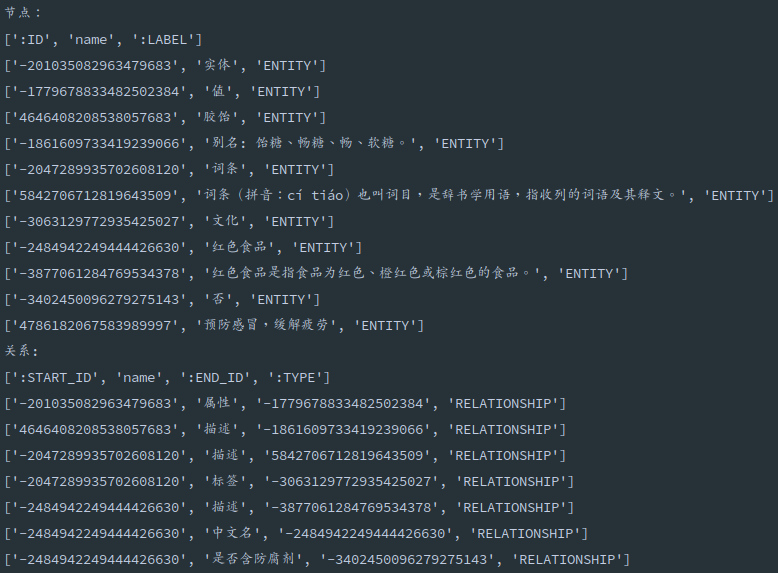
entity.csv —— 作为图数据库中的实体::ID,name,:LABEL
| :ID | name | :LABEL |
|---|---|---|
| 实体id(不可重复) | 实体名 | 实体标签 |
rel.csv —— 作为实体的关系: :START_ID,name,:END_ID,:TYPE
| :START_ID | name | :END_ID | :TYPE |
|---|---|---|---|
| 实体ID | 关系名 | 实体ID | 类型 |
因此,首先在阿里巴巴清洗后的文本基础上将文件格式转成符合我们要求的格式。限于篇幅,代码这里就不贴了,如果有需要可以给我留言。最终转成的数据格式如下,使用Python读出了前10行:
转成需要的格式之后即可准备进行导入。首先将转换后的两个文件放入neo4j安装路径下的import文件夹。如果不知道在哪,可以通过Neo4j desktop打开本地的一个图数据库,点击Manage:

点击open folder即可打开import文件夹。
由于版本差异,上述文章中的导入命令无法运行,经过修改测试,个人使用如下格式成功进行导入:
./neo4j-admin import --database graph.db --nodes=../import/vertex_new_form.csv --relationships=../import/edge_new_form.csv --ignore-extra-columns=true --skip-duplicate-nodes=true --skip-bad-relationships=true
注:网上很多版本说需要先删除databases文件夹下的graph.db文件夹,从本人测试来看,完全不需要,上述命令中的graph.db可任意更换名称。
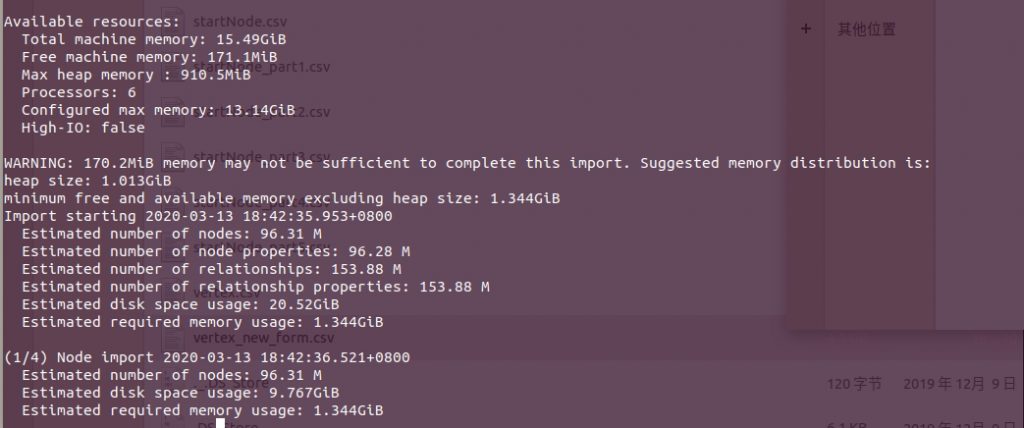
如果数据运行正确,会出现一下画面,首先确定导入需要的资源(对内存还是有一定要求的):
接着导入节点:

导入关系:

建立关系:
完成:

最终导入,csv格式中还是有错误的数据,因此设置了 skip-bad-relationships:
IMPORT DONE in 19m 10s 463ms.
Imported:
45464785 nodes
139916576 relationships
185380388 properties
Peak memory usage: 688.9MiB
There were bad entries which were skipped and logged into
下面即需要将数据库进行展示,新建的graph默认有两个数据库,对应databases文件夹下的两个文件夹:neo4j和system。不知道为何使用上述命令导入之后新增的graph.db(名字和命令中的database参数有关)无法显示,也可能是本来就不会显示。。。

没办法,只能通过其他办法。对比了一下几个文件夹下的内容,发现可以将graph.db先dump再载入到现有的某个数据库几个,成功实现:
进入到安装目录的bin文件夹下,需要先新建好 dump 文件的目录:dump:
./neo4j-admin dump --database=graph.db --to=../backups/graph/2020-3-16.dump
在load到现有的数据库中,因为我原有的两个数据库是空的,不清楚是否会抹除已有的数据(when use –force option, any existing database gets overwritten),load:
./neo4j-admin load --from=../backups/graph/2020-3-16.dump --database=neo4j --force
更多参数参考: https://neo4j.com/docs/operations-manual/current/tools/dump-load/
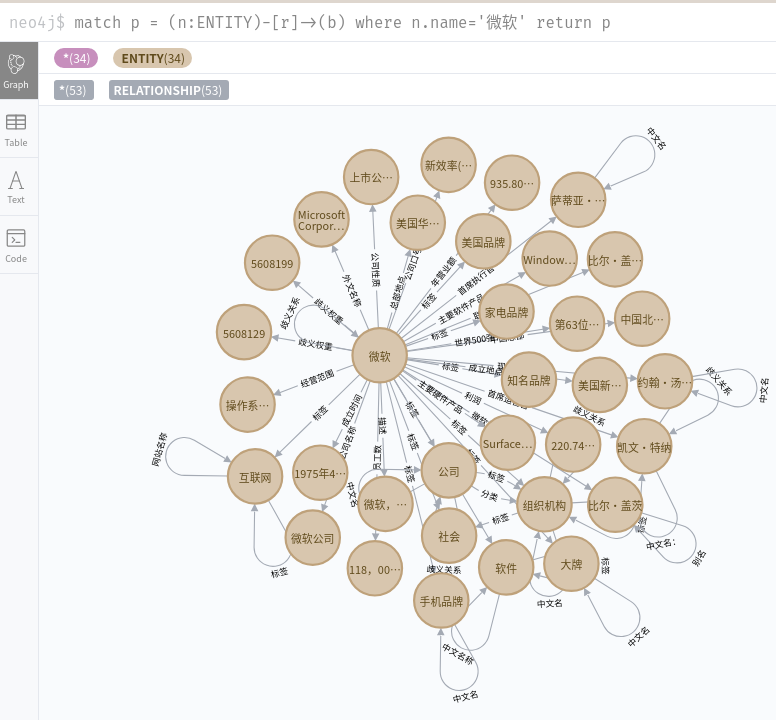
接下来,在graph中选择你导入的数据库即可看到了,简单查询一下:
后续工作:
- 由于数据量较大,检索的时间较慢,后续看看有哪些优化查询速度的;
- 个人使用知识图谱主要服务于智能问答,下一步就是思考如何结合知识图谱做好智能问答了,有兴趣的小伙伴可以去这里试试我的智(智)能(障)问答。
update: 针对第一条,发现将检索的范围指定能加快检索速度,即:
MATCH p = (n1:ENTITY)-[r:RELATIONSHIP]->(n2:ENTITY) where n1.name ="微软" RETURN p
留言
大神,我也在尝试将ownthink的数据导入到neo4j,任务时间比较紧,请问“在阿里巴巴清洗后的文本基础上将文件格式转成符合我们要求的格式。”的python代码是什么,请赐教!!!
这个是你邮箱么?
请问可不可以分享一下博主的代码
求导入neo4j的转换代码
已发邮箱
求导入neo4j的转换代码, 另外,转换后的数据格式能否导入virtuoso?,有无相关转换代码?
已发邮箱。 转换后的数据格式能否导入virtuoso—— 不能确定,你可以看看能不能从Neo4J导出数据到virtuoso,可能更方便
想看代码学习下
已发邮箱
大佬,分享一下python代码吧,邮箱已留。
已发邮箱
求分享python代码,谢谢
已发至邮箱
求格式转换代码
已发送
感谢博主分享,想要清洗数据的代码看一下~
已发送
谢谢博主分享, 想要清洗数据的代码看一下~~~~~~
已发邮箱
感谢博主分享,求一下清洗数据的代码
已发邮箱
谢谢博主分享, 求一下数据清洗的代码~
已发邮箱
求导入neo4j的转换代码
已发邮箱
谢谢博主分享
再请教下kg_v2.tar.gz 是ownthink_v2.csv 处理后的数据吗? 我打开https://nebula-graph.oss-accelerate.aliyuncs.com/ownthink/kg_v2.tar.gz这个链接时出现下面提示,这是为什么呢?多谢博主 AccessDenied You do not have read permission on this object. 5EE9C5E833FDC3B171765BBF nebula-graph.oss-accelerate.aliyuncs.com
应该是阿里简单处理后的数据,但不符合neo4j导入的要求。出现这个可能是资源被删了吧,我补个下载链接吧
你好,资源被删了,能不能麻烦补发个下载链接给我呢?另外能不能同时发一下导入neo4j的转换代码给我呢? 非常感谢。
感谢分享,求格式转换代码,非常感谢。
感谢楼主分享,刚入门Neo4j的小白求一份数据格式转换的代码,非常感谢。
已发邮箱
您好,请问能不能分享给一下楼主给您的数据转换的代码,万分感谢。
感谢您的精彩分享,求一份数据格式转换的代码,非常感谢!
已发
你好,能不能发一份数据格式转换的代码给我呢? 非常感谢! 另外 打开https://nebula-graph.oss-accelerate.aliyuncs.com/ownthink/kg_v2.tar.gz这个链接时出现下面提示,有其他源的下载链接吗? 麻烦您啦,非常感谢。 AccessDenied You do not have read permission on this object. 5EE9C5E833FDC3B171765BBF nebula-graph.oss-accelerate.aliyuncs.com
我找了一下那个文件被我删掉了,网上有一份不知道是不是这个格式的: https://pan.baidu.com/s/1LZjs9Dsta0yD9NH-1y0sAw 提取码: 3hpp 解压密码是:https://www.ownthink.com/
好的,谢谢您。 方便的话能不能把数据格式转换的代码也发下给我呢? 麻烦啦。
已发邮箱
感谢大神的分享,能否把“数据格式转换的代码“发我信箱啊,非常感谢!
已发邮箱
大神 求一份转换代码
谢谢您。 我下载了一下,这份是清洗前的知识图谱数据,ownthink_v2.csv。
能分享下清洗后的数据和清洗代码吗?
博主可以分享下清洗后的数据和清洗代码吗?~谢谢!
阿里云清洗后的数据我本地也没有了。如果需要可以直接给你Neo4j的备份,你直接导入就行了
可以给一份备份吗 大神
阿里清洗后的那个文件我没有了 我的代码是基于阿里清洗后的文件去转换的,如果需要的话我发给你
楼主你好!清洗后的csv已经无法下载。。。能给我发一份neo4j的备份吗?我想直接导入,万分感谢!
楼主您好!可以给Neo4j的备份吗,想直接导入!感谢!
好的,发你邮箱
您好,能发一份导入neo4j的数据格式,和导入的代码吗 ? 78879011@qq.com 谢谢
https://1drv.ms/u/s!AriBPJP1-uJAgdRM7cW-yJAY0-DT-Q?e=bAiUXl 密码:neo4j 这是导入neo4j的备份文件。 从该文件导入到数据库的命令可在本文找到。
转化格式代码,麻烦您发一下么?谢谢
转换的代码是基于阿里清洗过后的那个文件,现在那个文件好像没了。你要是需要的话我可以发你可以直接导入到neo4j的备份,通过dump 导入就行了
楼主您好!,阿里清洗的数据下载不了了,可以给Neo4j的备份吗,想直接导入!感谢!
https://1drv.ms/u/s!AriBPJP1-uJAgdRNRcSE99_MnxjSzg?e=MAAjot 可能需要翻墙
感谢分享,非常棒棒~
谢谢喜欢~
您好,资源失效了,您还方便发一下吗?
https://1drv.ms/u/s!AriBPJP1-uJAgeFqKXLSDwyU2oz8bw?e=vRmWal 密码:0000 是可以直接导入的格式关系和实体格式。 你再按照文章进行导入吧
不好意思,打扰您了。资源失效了,可以再分享一次备份的neo4j数据吗?
https://1drv.ms/u/s!AriBPJP1-uJAgeFqKXLSDwyU2oz8bw?e=vMmPDJ 密码:0000 这是我转换之后的节点和关系数据,你按照文章后面的import 方式应该能成功
大佬,自己尝试了一下,电脑配置太差,导不进去,可以发一份neo4j数据备份么?万分感谢
2714589791@qq.com
已发
大佬,不好意思,打扰您了。资源失效了,可以再分享一次备份的neo4j数据吗?
已发你126邮箱
可以分享一下您处理数据的代码嘛, 谢谢
已发邮箱
大佬您好,能分享一下您数据处理的代码嘛,谢谢了
已发邮箱
可以分享一下您处理数据的代码嘛, 谢谢
已发邮箱
大佬您好,能分享一下您数据处理的代码和处理后的数据吗嘛,感谢啦
请问能否发一份 neo4j 的数据和导入命令吗?感谢!!
你好,能发我一份备份的neo4j数据吗? 979500717@qq.com
博主您好,最近导师让快速搭建一个对话系统,数据还没有,我想先试试通用知识图谱,可以分享下清洗后的数据和清洗代码吗?万分感谢!
大神你好,求一份导入neo4j的转换代码,感谢感谢
你好,大佬,方便发一份数据库备份文件吗?485084041@qq.com
大佬,可以分享一下数据库备份文件吗?
备份的资源失效了 能在分享下备份吗 也麻烦帮忙发下清洗的代码吧
您好,我想导入owthin的数据,看了您的教程,发现下标是用哈希处理的,问下有什么讲究吗,解决热点查询问题吗。我用了三天时间尝试,4.0版一下的不管是社区还是企业 对关系上限都是65536 无符合短整形 存不下过多的关系,100w的数据关系数量已经十几万了。我看了官方文档,4.0以后对关系上线用highlimit能解决限制,但是您的博客里 import命令没有写,请问是怎么处理的。 我还发现,不做索引的情况下,社区版本一分半 企业版五分钟。。。人傻了 能不能指教一下,或者分享下代码
您好,可以分享一下格式转换的代码和转换后的导入数据吗,谢谢!
您好,可以分享一下格式转换的代码和转换后可以直接导入的数据吗,谢谢!
不好意思,打扰您了。资源失效了,可以再分享一次备份的neo4j数据吗?